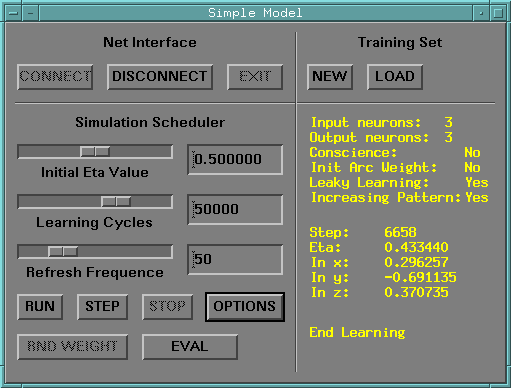
SIMPLE MODEL
in the MODEL
sub-menu is choosen.
Unsupervised competitive learning: an overview
In competitive learning only one output unit, or only one per group, is on at a time. The output units compete for being the one to fire, and therefore they are often called winner-take-all units.The aim of such networks is to cluster or categorize the input data. Similar inputs should be classified as being in the same category and should fire the same output unit.
Categorization has obvious uses for any artificially intelligent machine trying to understand its world. It can be used for data encoding and compression through vector quantization, in which an input data vector is replaced by the index of the output unit that it fires. It also has applications to approximation of functions, image processing, statistical analysis and combinatorial optimization.
Competitive networks have some rather generic disadvantages over
distributed representations:
- They need one output cell for every category involved.
- They are not robust to degradation or failure; if one output unit fails then we lose the whole category.
- They cannot represent hierarchical knowledge; there is no way to have categories within categories.
Simple competitive learning model: an overview
The simplest competitive learning networks are based upon the standard competitive learning rule.Such networks consists of a single layer of output units fully connected to a set of inputs.
As the principal aim of this kind of alogorithms is to categorize the input data, the output level should have a number of units equal to the number of categories.
Only one of the output units, the winner, can fire at a time. The winner will be the unit with the largest net input. If the weights for each units are normalized then we can say that wi* is the winner unit if ||wi* - I|| <= ||wi - I|| with i going from 0 to the number of output units. So the winner is the unit with normalized weight vector w closest to the input vector I.
Learning phase:
- Step 1
To start the learning phase we have to set all the weights with small random values. We choose them random because any symmetry between the weights values has to be broken.
- Step 2
Then we can aplly our set of input patterns I to the network.
- Step 3
For each input an output unit will be choosen as the winner unit with the rule we have seen above.
- Step 4
Now the network updates the weights wi*j for the winning unit only, to make the wi* vector closer to the current input vector Im.
- Step 5
Repeat from step 2 until the end of the input set.
We use the standard competitive rule to update the weights:

With INNE we can see how this works in a geometrical way in 2 or in 3 dimension.
We can consider a case with 3 input units.
So, every input pattern will be a three-dimensional vector I=(x,y,z).
It is easy to see how this vector can be considered a point in a three-dimensional space.
The weights vector wi of every output unit i also corresponds to a point in the
same space.
When we start the learning phase, we present to the network a set of points.
The result is that the winner will try to be the closest point of the input
pattern.
So if our input patterns are organized as a few group of close point,
every output unit weights vector will try to find the center of mass
of these groups.
Dead units
Some solution to prevent this situation are:
- We can initialize the weights to samples from the input itself, thus
ensuring that they are all in the right domain.
- We can update the weights of all the losers as well as those of the winners
with a much smaller eta. Then a unit that has always been losing will gradually
move towards the average input direction. This has been called leaky learning.
- We can turn the input patterns on gradually, using aIm + (1-a)v, where v
is some constant vector to which all the weights vectors wi are initialized.
As we turn a up gradually from 0 to 1 the pattern vectors move away from v
towards Im.
- We can subtract a bias term mi from wi*I and adjust the threshold to make
it easier for frequently losing units to win. Units that win often should raise their mi,
while the losers should lower them. This has been called conscience.
The Simple competitive learning rule module
The panel to drive the simulation
with its option panel allowing to select the learning rule.
 Back to index
Back to index