New Paper Accepted: Protecting machine learning from poisoning attacks: A risk-based approach
Our paper entitled Protecting machine learning from poisoning attacks: A risk-based approach has been accepted for publication in the journal Computers & Security.
In this paper, we propose a novel methodology to strengthen the robustness of ML against poisoning attacks, particularly semi-targeted poisoning attacks (i.e., attacks against a specific class). We propose an approach inspired by risk management, where we analyze each data point from different angles, compute the corresponding risk value, and train an ensemble of ML models with data points routed to the training sets of the models in the ensemble according to the retrieved risk value.
This work is a collaboration between our group at SESAR Lab, Università degli Studi di Milano and C2PS (Centre for Cyber-Physical Systems), Khalifa University, Abu Dhabi, UAE.
The authors of the paper are: Nicola Bena (me), Marco Anisetti, Ernesto Damiani, Chan Yeob Yeun, and Claudio A. Ardagna.
Below is the full abstract.
The ever-increasing interest in and widespread diffusion of Machine Learning (ML)-based applications has driven a substantial amount of research into offensive and defensive ML. ML models can be attacked from different angles: poisoning attacks, the focus of this paper, inject maliciously crafted data points in the training set to modify the model behavior; adversarial attacks maliciously manipulate inference-time data points to fool the ML model and drive the prediction of the ML model according to the attacker’s objective. Ensemble-based techniques are among the most relevant defenses against poisoning attacks and replace the monolithic ML model with an ensemble of ML models trained on different (disjoint) subsets of the training set. They assign data points to the training sets of the models in the ensemble (routing) randomly or using a hash function, assuming that evenly distributing poisoned data points positively influences ML robustness. Our paper departs from this assumption and implements a risk-based ensemble technique where a risk management process is used to perform a smart routing of data points to the training sets. An extensive experimental evaluation demonstrates the effectiveness of the proposed approach in terms of its soundness, robustness, and performance.
The paper is available here (open access).
A Quick Overview
Our risk-based approach consists of two main phases: risk assessment and risk treatment (see the figure below).
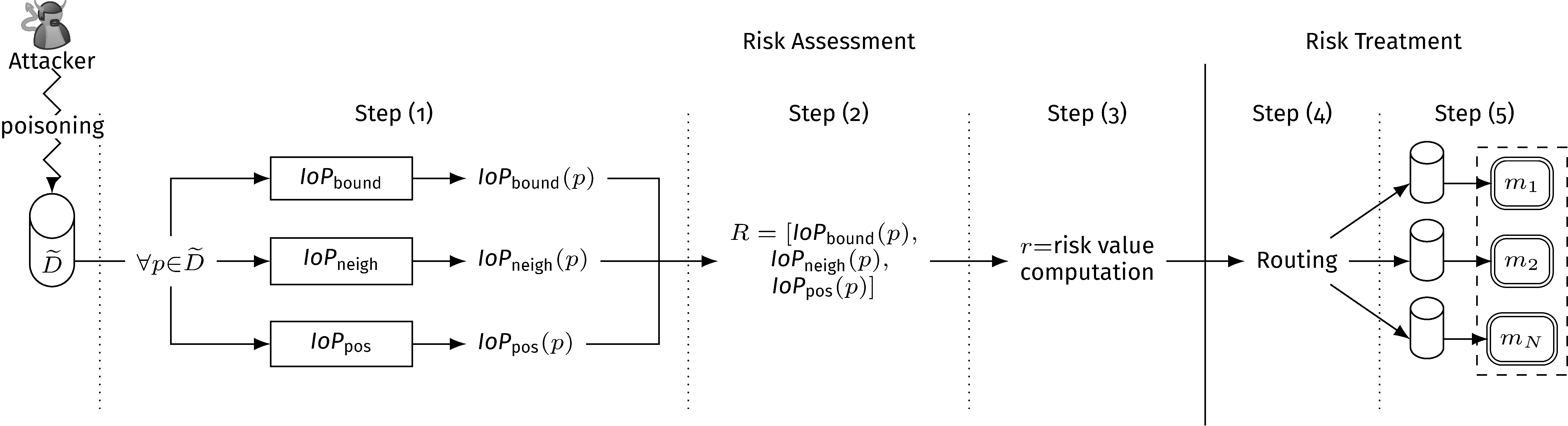
Risk Assessment
Here, we use a set of Indicators of Poisoning (IoPs), each of which analyzes each data from different angles, basically returning a value in [0, 1] indicating the poisoning risk according to the analysis the IoP performed.
Though the approach is generic, we considered three IoPs:
- boundary: the smaller the distance from the (approximated) classification boundary, the higher the risk
- neighborhood: the higher the distance from neighbors of the same class and the smaller from the neighbors of the opposite class, the higher the risk
- position: the closer to the opposite class and the farther from its own class, the higher the risk
Then, we aggregate the (discretized in [0, 1]) output of the IoPs, for each data point, and obtains an individual value in [0, 1] modeling the poisoning risk. We implemented two alternatives for this step:
- count: counts the number of IoPs whose output is 1
- max: returns 1 if at least one IoP returned 1, 0 otherwise
Risk Treatment
Here, we train an ensemble of ML models. Each model is trained on a disjoint subset of the original training set (the union equals the initial training set). We call routing the process of deciding the training set of each data point.
We implemented two alternatives:
- round-robin: fairly distribute data points with the same risk values to each training set
- sink: routes data points with the highest risk value to the first model, then assigns the remaining ones using round-robin.
We then train the models independently. At inference time, we use hard majority voting.
Evaluation
Process
The evaluation we run is quite complex and long, so here I briefly summarize it.
We implemented two semi-targeted poisoning attacks, we called Boundary and Clustering, and evaluated our approach varying
- the percentage of poisoning budget in {2, 3, 4, 5, 6, 7, 8, 9, 10, 11}
- the number of models in the ensemble in {3, 9, 15, 21, 27, 33}
- the datasets in Musk2 and Spambase
We used decision tree as base model in the ensemble, and first executed train-test split (75-25). Then, given: a poisoning attack, the values of the poisoning budget, an instance of our risk management process (the IoPs + one alternative for risk computation + an alternative for risk treatment, called risk pipeline), the number of repetitions, we followed these steps:
- poisoning, applying the attack on the training set for each value of the budget
- training of the vanilla model (decision tree) on the clean and poisoned training sets. Training of the filtered model (decision tree removing poisoned data points) from he clean and poisoned training sets. We computed accuracy, precision, recall, and re-executed this step according to the number of repetitions (5) and averaged the values of the metrics
- training of the ensemble, repeated also according to the number of repetitions (5)
- evaluation, computing the difference of a given metric between a reference (ensemble) and base model (vanilla). This difference is called delta.
Results (Excerpt)
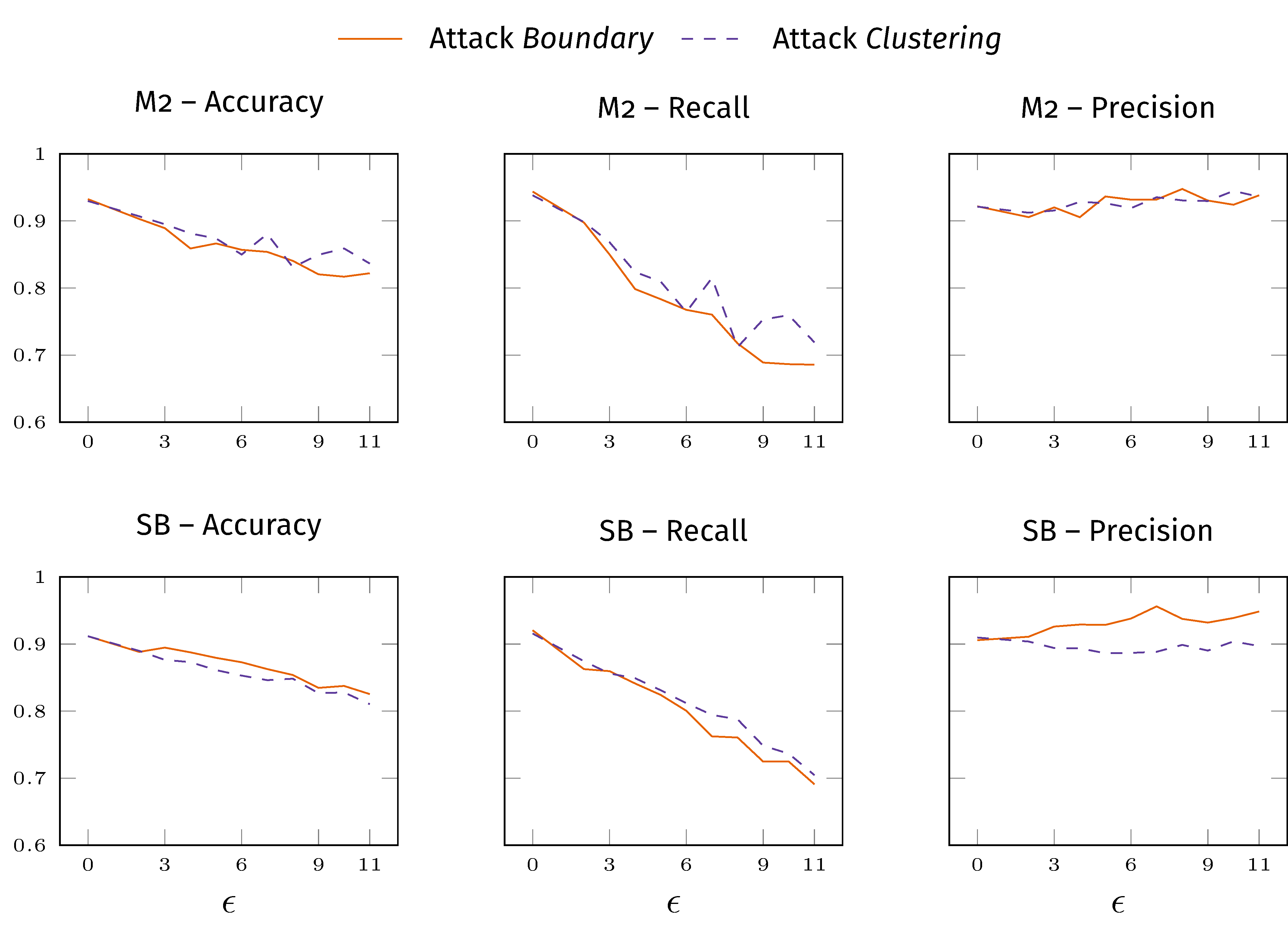
First, we evaluated the impact of the attacks against the vanilla model, finding that, as expected, recall has the highest impact, as shown below.
Second, we implemented an oracle pipeline, where the risk value is assigned according to an oracle knowing which points are poisoned. This is our optimum.
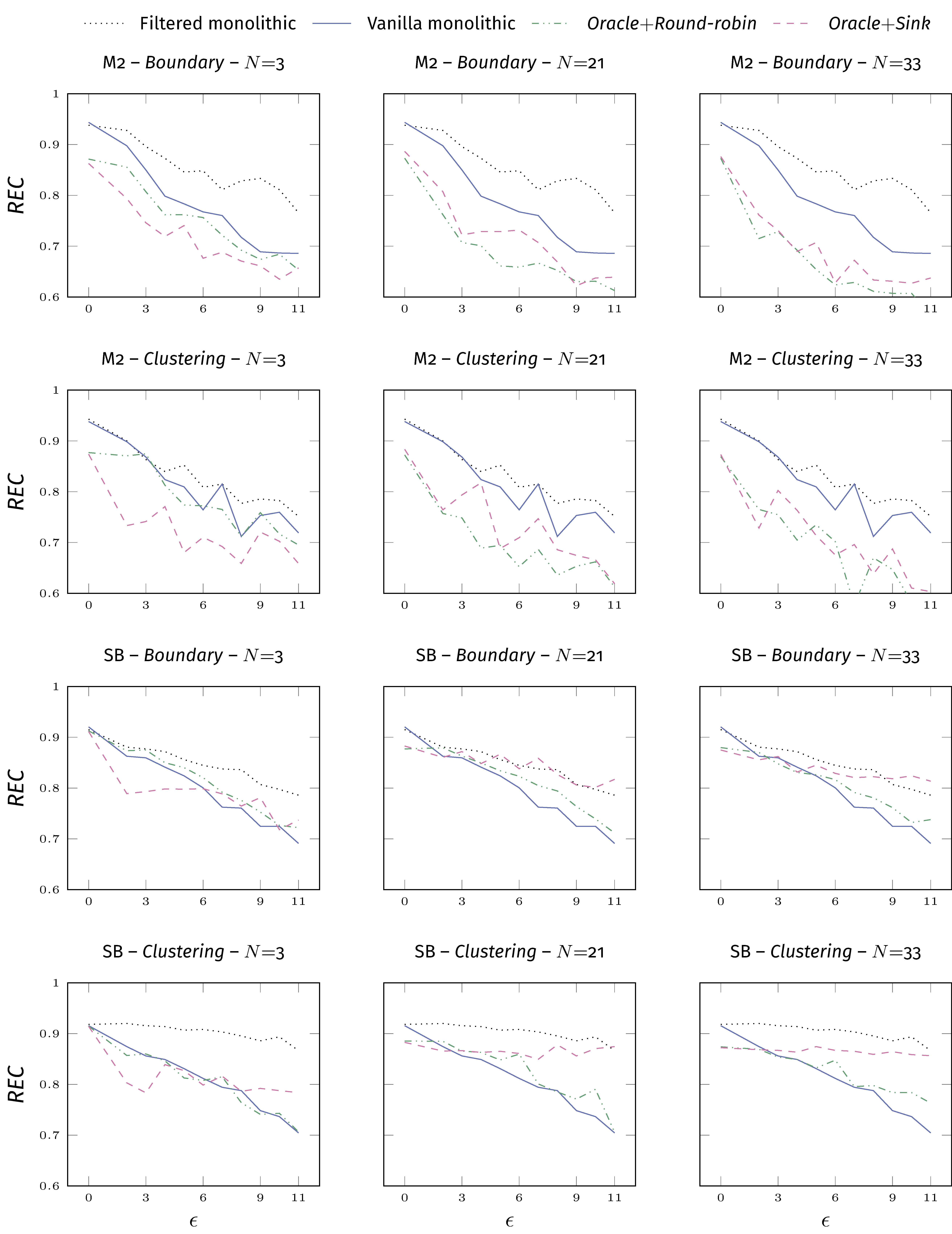
We see that the oracle is indeed strong on dataset Spambase, but on Musk2 (reason: Musk2 is a very weak dataset).
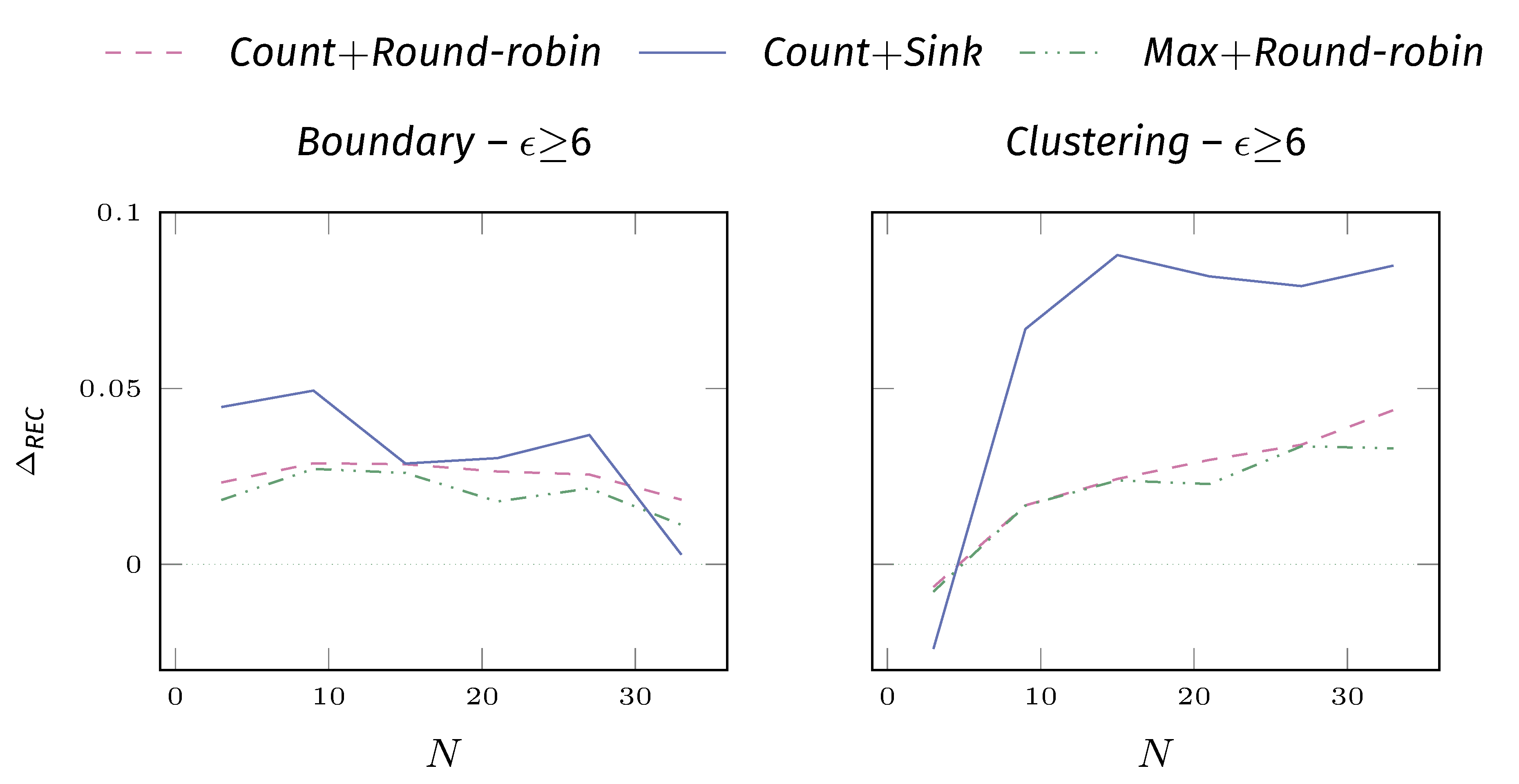
Now, how good are the actual risk pipelines? We measured the delta against the vanilla model: values larger than 0 indicates that the risk-based ensemble is better.
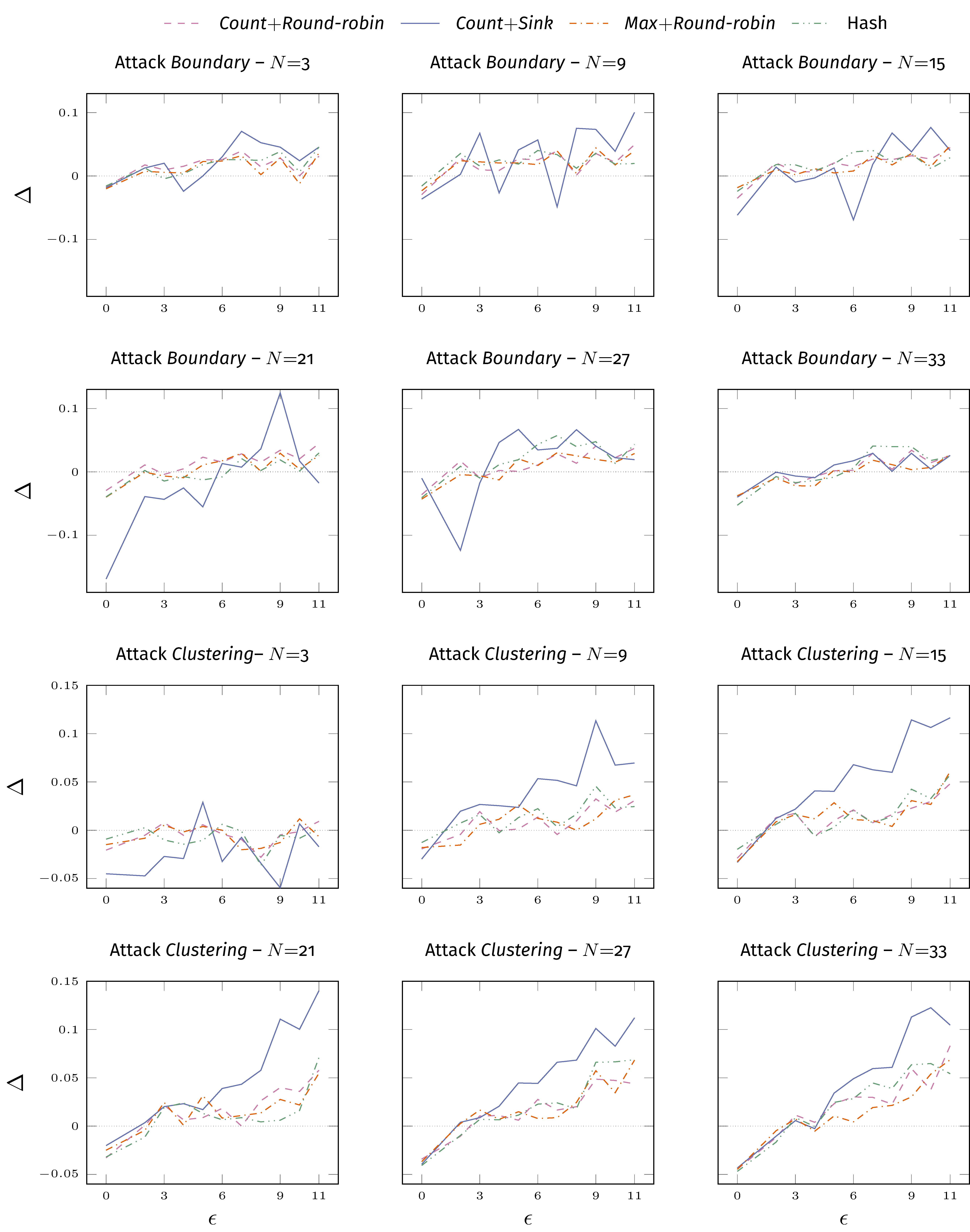
Let’s also see the impact of N.