Next: Experimental results Up: A mathematical model for Previous: Third step: adding noise
We propose here a simple procedure for evaluating and comparing feature selection methods, although other different approaches can be applied by using the synthetic data obtained from our mathematical model.
Suppose we want to compare and evaluate ![]() feature selection methods
feature selection methods ![]() ,
,
![]() , on a single artificial dataset
, on a single artificial dataset ![]() created by using the proposed model.
created by using the proposed model.
Denote with ![]() the set containing all the
genes included in two distinct expression profiles.
If
the set containing all the
genes included in two distinct expression profiles.
If ![]() is the total number of genes, we have
is the total number of genes, we have
![]() .
The result produced by each feature selection method
.
The result produced by each feature selection method ![]() consists of a list
consists of a list
![]() , with the
, with the ![]() more relevant genes
identified by the method
more relevant genes
identified by the method ![]() .
We can evaluate the
performance of the method
.
We can evaluate the
performance of the method ![]() as the fraction
as the fraction ![]() of
overlapping between the set of the true relevant genes
of
overlapping between the set of the true relevant genes ![]() and the set
and the set ![]() of the genes identified by the method
of the genes identified by the method ![]() .
.
We can compare the performances of the ![]() methods by ordering the
methods by ordering the
![]() values, for
values, for
![]() . In particular, the higher is the
value
. In particular, the higher is the
value ![]() , the more effective is the corresponding method
, the more effective is the corresponding method ![]() .
.
Since this comparison, based on a single data set, may lead to
unreliable conclusions,
the procedure can be repeated for a fixed number ![]() of different instances
of different instances
![]() , with
, with
![]() , obtained from the same mathematical model. Thus, for each method
, obtained from the same mathematical model. Thus, for each method ![]() , we obtain a
vector
, we obtain a
vector
![]() whose
whose ![]() -th
component
-th
component ![]() ,
,
![]() , is the overlapping
between the relevant genes of the
, is the overlapping
between the relevant genes of the ![]() -th dataset
-th dataset ![]() , and the set of the first
, and the set of the first
![]() genes obtained by applying the method
genes obtained by applying the method ![]() on
on ![]() .
.
For the sake of simplicity the procedure has been schematized in
Tab. 3, where each row represents a different
feature selection method and each column corresponds to a different dataset. The
comparison between two methods ![]() and
and ![]() is simply given by counting how many
components of the
is simply given by counting how many
components of the ![]() -th row vector are higher than the
corresponding components of the
-th row vector are higher than the
corresponding components of the ![]() -th one, or by calculating the mean and the standard
deviation of the corresponding row vector.
-th one, or by calculating the mean and the standard
deviation of the corresponding row vector.
| Data set | ||||||
| Feature | ||||||
| selection |
|
|||||
| method | ||||||
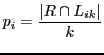 ,
,